| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | |
| 这个作业的要求在哪里 | |
| 我在这个课程的目标是 | 了解人工智能,提高编程能力 |
| 这个作业在哪个具体方面帮助我实现目标 | 了解神经网络的基本工作原理,理解梯度下降 |
一、梯度下降的实现
代码
大家都写得差不多的 没什么意义的 你可以跳过的引用、读取文件、赋初值部分
import numpy as npimport matplotlib.pyplot as pltimport randomfrom pathlib import Pathx_data_name = "TemperatureControlXData.dat"y_data_name = "TemperatureControlYData.dat"eta = 0.1 #这几个参数还要再改滴max_epoch = 100batch_size = 5w = 1 b = 1def ReadData(): #读取X,Y数组 Xfile = Path(x_data_name) Yfile = Path(y_data_name) if Xfile.exists() & Yfile.exists(): X = np.load(Xfile) Y = np.load(Yfile) return X.reshape(1,-1),Y.reshape(1,-1) else: return None,NoneX, Y = ReadData()LOSS=[]
没有定义很多函数的 全部堆在一块的 甚至没有用数组点乘的 显得好low好low的o(╯□╰)o 但是实现要求的主程序来啦!
if __name__ == '__main__': for i in range(max_epoch): batch_list = [random.randint(0,199) for _ in range(batch_size)] #随机生成数组 for j in range(batch_size): batch_x = X[0,batch_list[j]] #根据随机生成的数组选取数据x,y batch_y = Y[0,batch_list[j]] z = w * batch_x + b dz = z - batch_y #计算梯度 dw = dz * batch_x / batch_size db = dz / batch_size delta_w = dw.sum() delta_b = db.sum() w = w - eta * delta_w #更新w,b b = b - eta * delta_b loss = ((z - batch_y) **2 / batch_size).sum() #损失函数 LOSS.append(loss) print("w=%f,b=%f"%(w,b)) plt.plot(LOSS) plt.title("MiniBatch batch_size=%d eta=%f"%(batch_size,eta) ) plt.xlabel("epoch") plt.ylabel("loss") plt.show() 损失函数
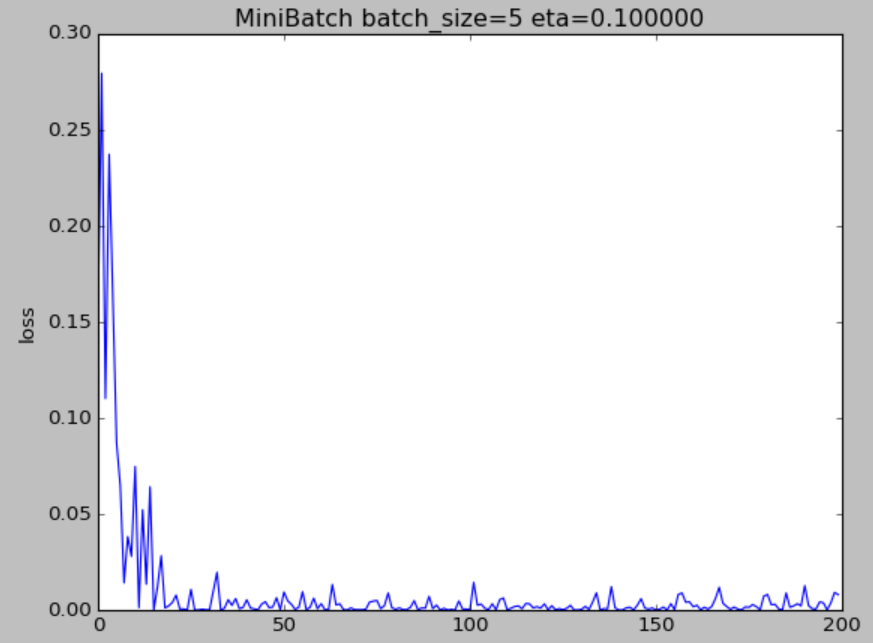

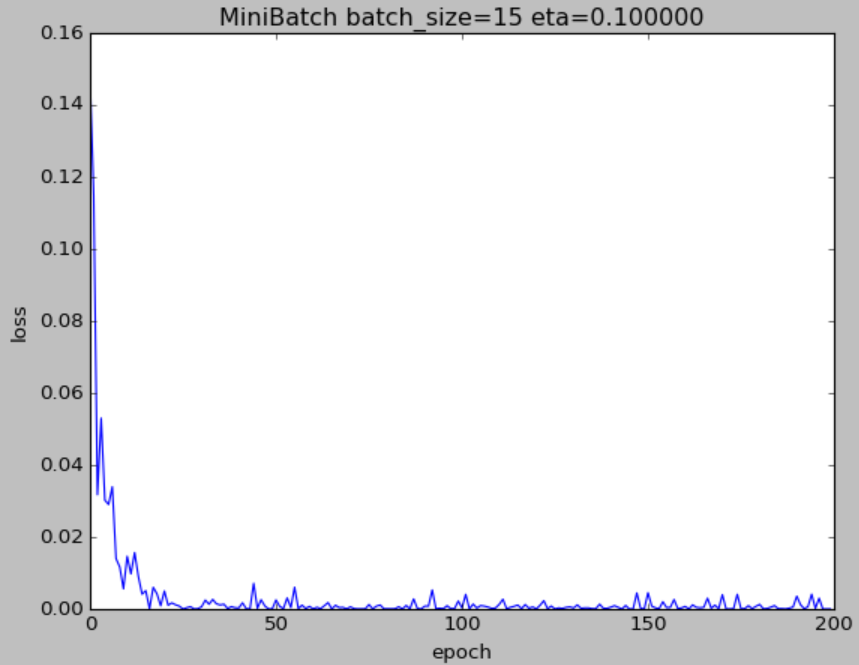
反思
- 我用的随机方法是随机生成1-200之间的十个数,对应X,Y数组中的数据。应该也可以每次都把数组顺序打乱,取前batch_size个数据。
- 随机选取数据,结果真的太玄学了!同样的代码跑两遍,损失函数可能一个无比难看一个比较光滑。都不好总结规律了。
- 一开始max_epoch选了50,到最后几组非常不光滑,那个波动都不能叫毛刺了应该叫波浪。现在改成200,光滑了很多,但毛刺也不少。
- w和b的初值,一开始我用的是随机函数生成,这样图像就更不光滑更难看了,连续跑两遍的差别也就更大了,还是改成定值吧。
- 关于学习率的改变,影响非常大。选取eta=0.05的时候,损失函数一开始忽上忽下,变化巨大,取到0.2的时候,损失函数就一泻千里长跪不起了。并且w和b最后的值随着eta的变化,变化得也很大,w大约有0.2的波动,b波动小一点但也接近0.1了。
二、思考题
1、损失函数的 2D 示意图为什么是椭圆而不是圆?如何把这个图变成一个圆?
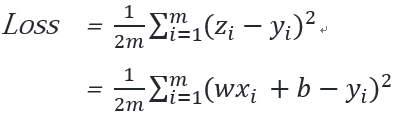
2、为什么中心是个椭圆区域而不是一个点?
如果是一个点,那么该点就是loss=0的点。但实际上损失函数无限趋近于0而不可能精确为0,此时这些渐近的点形成了椭圆区域。